
Citespace使用教程
Citespace使用教程
1 各种文献分析软件
| 工具 | 网络分析 | 网络可视化 | 热度图 | 转折点 | 聚类自动命名 | 宏观理论 | 双图叠加 | 概念树 | 时间线 |
|---|---|---|---|---|---|---|---|---|---|
| CiteSpace | ++ | ++ | + | + | + | + | + | + | |
| VOSViewer | + | ||||||||
| CitNetExplorer | + | + | |||||||
| SCI2 | + | ++ | |||||||
| Pajek | +++ | + | |||||||
| Gephi | ++ | +++ |
2 Citespace分析和可视化
红色的词代表突发性的词,根据不同的颜色划分不同的实践段,通过分区分不同的研究领域
Citespace主要分析和可视化方法:
地图叠加
网络分析
文本分析
- 地理地图叠加可视化
- 宏观双图叠加可视化
- 时间序列网络可视化
- Cluster View
- Timeline View
- Timezone View
- 结构变异轨迹
- 引用趋势可视化
- Burst View
- 文本可视化
- 概念树
3 Citespace分析基本步骤
3.1 分析基本步骤
- 准备数据
- 整理数据
- 地理数据叠加
- 学科关联双图叠加
- 网络可视化
- 概念树
- 解读
3.2 收集数据
3.2.1 可分析数据库
Citespace可以进行引文分析的数据库:
带有引文的科学文献数据
- Web of Science Core Collection
- Scopus
- CSSCI
- CSCD
缺少引文的科学文献数据
- Web of Science中其他数据库
- MEDLINE / Pubmed
- CNKI
3.2.2 网络分析
(1) 共被引网络分析
- 文献共被引,作者共被引,期刊共被引
(2) 共现网络分析
-
合作网络:作者,机构,国家,地理位置
-
共词:关键词,学科索引,名词短语
(3) 文献耦合网络分析
3.2.3 分析和解读策略
方法:
-
由浅入深地理/宏观双图叠加,聚类图,时间线,等等
-
学科分类,关键词,被引文献
范围:从整体到局部聚类:从大到小
时间:由远到近
色彩:由鲜艳(重要)到平淡
字体:由大到小
标签:LSI, LLR, MI
指标:burst, 中心性, sigma, u180
3.2.4 要点
- CiteSpace提供了几种分析科学文献的方法;
- 参照分析和解读策略制定最有效而系统的分析方案;
- 解读时综合运用科学发展的宏观理论;
- 认真区分数据和可视化所表现的来自其它来源的信息。
4 安装和功能介绍
4.1 Citespace下载安装
首先确定自己电脑的位数,根据自己电脑的位数下载对应的java位数。
Citespace下载页面:http://cluster.ischool.drexel.edu/~cchen/citespace/download/
选择对应的Java版本进行安装:https://www.oracle.com/java/technologies/downloads/#java8-windows
首先需要安装Java环境,其次再进行Citespace安装。
4.2 功能参数界面
进入的界面如下:
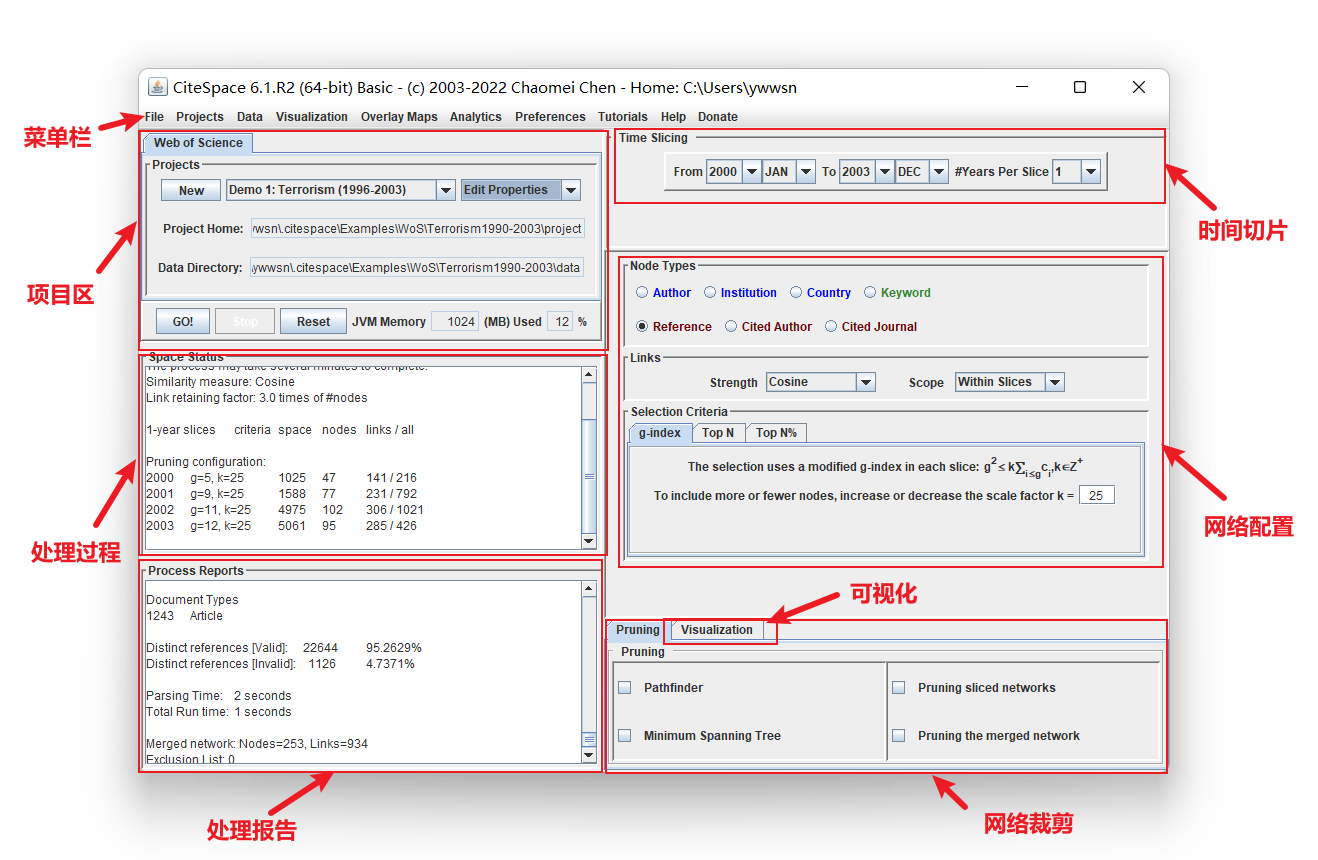
4.2.1 项目区
项目区图片如图所示:
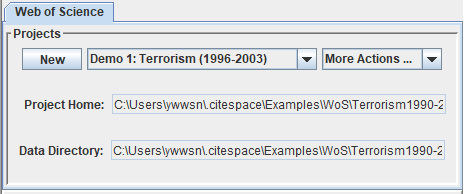
new是用来导入项目文件进行新的分析;Demo1:Terrorism(1996-2003)是当前所分析项目的名称;More Actions...是对当前的项目的再设定
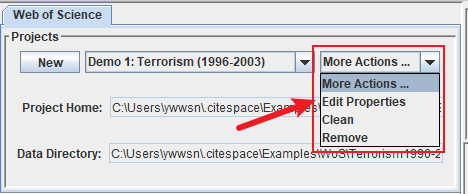
Project Home是自己建立的project文件夹文件,随着数据分析会产生很多结果文件,保存在此目录下。Data Directory是自己下载的原始数据,分析的时候会把路径加载到此位置。
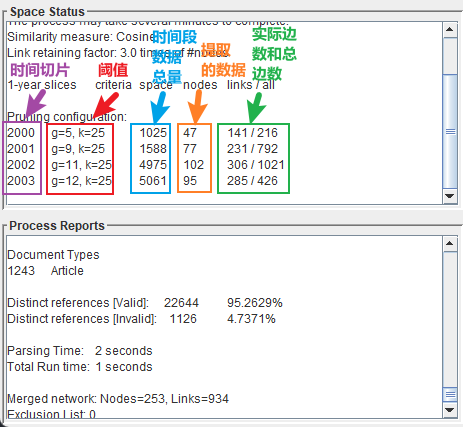
4.2.2 数据处理过程
数据处理窗口如下:
4.2.3 时间切片
对所下载的文献切片处理:
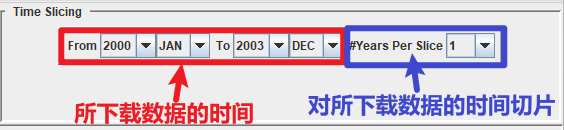
根据需要选择合适的时间切片。
4.2.4 节点类型选择
根据需要选择合适的节点进行分析:
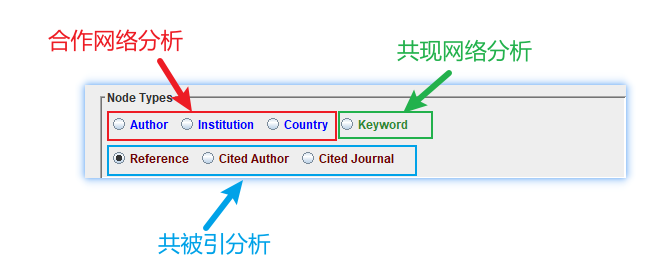
- 节点类型决定了使用CiteSpace分析的目的;
- 选择了节点类型,CiteSpace将从对应的字段来提取数据。例如,进行Keyword分析, CiteSpace将从数据中读取DE字段的数据,来提取关键词信息。
4.2.5 选择阈值
-
阈值,在数据处理中CiteSpace会按照用户设定的阈值提取出各个时间切片满足的文献,并最后合并到网络中
-
该步骤可以认为是对数据的精炼,以提取最具影响力的数据来进行可视化。
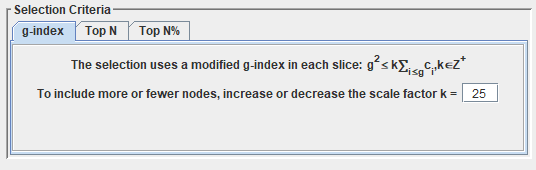
- g-index g指数分析
- Top N 分析被引次数前多少的文献
- Top N% 分析被引次数前百分之多少的文献
4.3 可视化界面介绍
点击运行之后,选择可视化可以进入可视化界面:

4.3.1 快捷功能区
快捷功能区如图:
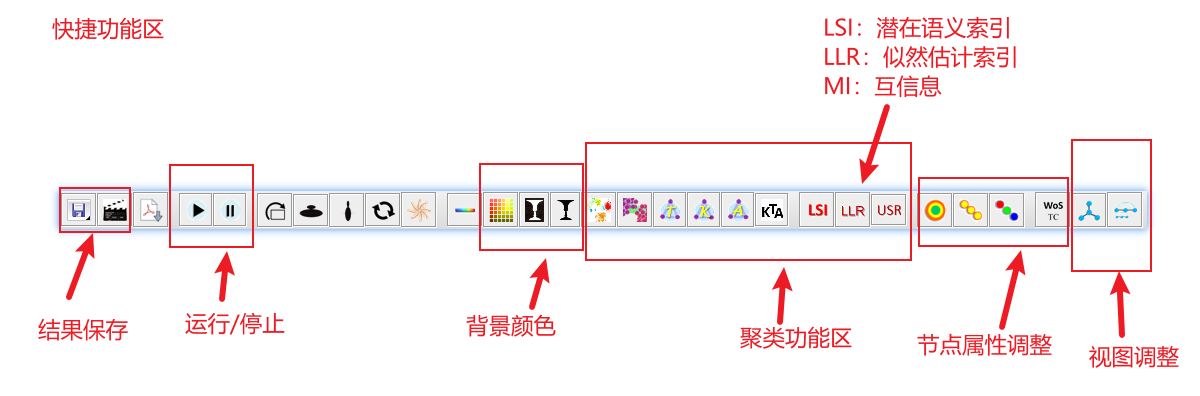
按下停止按键,可以让图形界面停止,选择自己喜欢的图形。
按下单色显示按键,图形颜色会显示单一颜色,效果如图:
4.3.2 快捷菜单
快捷菜单如图:
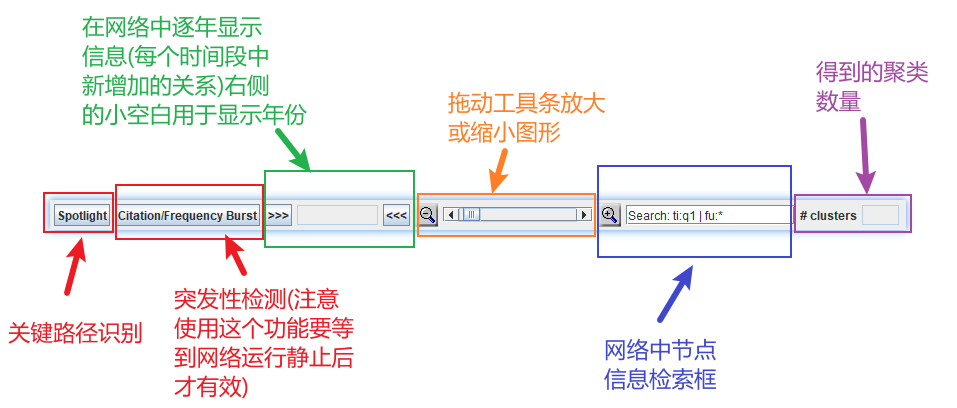
- Spotlight(聚光灯):突出显示中介中心性高的节点之间的连接
- Citation/Frequency Burst:显示英文突发的情况,能够看出论文激增或者突发情况。能够看出该领域哪些文献被突然关注起来,以及关注的变化过程。如下图:
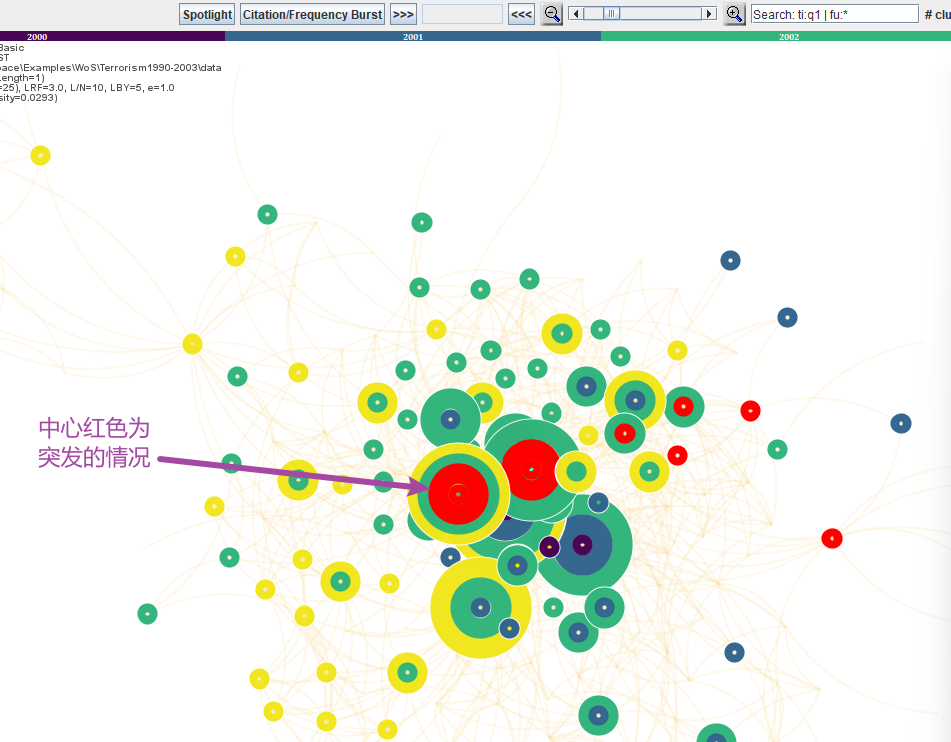
可以对图片进行放大缩小,在做博士论文的时候,可以通过文献分析这个领域,看看自己的研究方向是这个领域的哪个部分,并对这个部分进行放大进行进一步分析,以及现在的受关注情况,颜色越靠近色条右方,越是最近的研究热点
-
Link walkthrough:顺序显示对应年份的共被引连线,来考察网络的演化。
-
搜索框:可以在搜索框中搜索人名,分析两个人的兴趣、研究文献的广泛性以及对学科的贡献。
4.3.3 控制面板
控制面板标签模块调整如图:
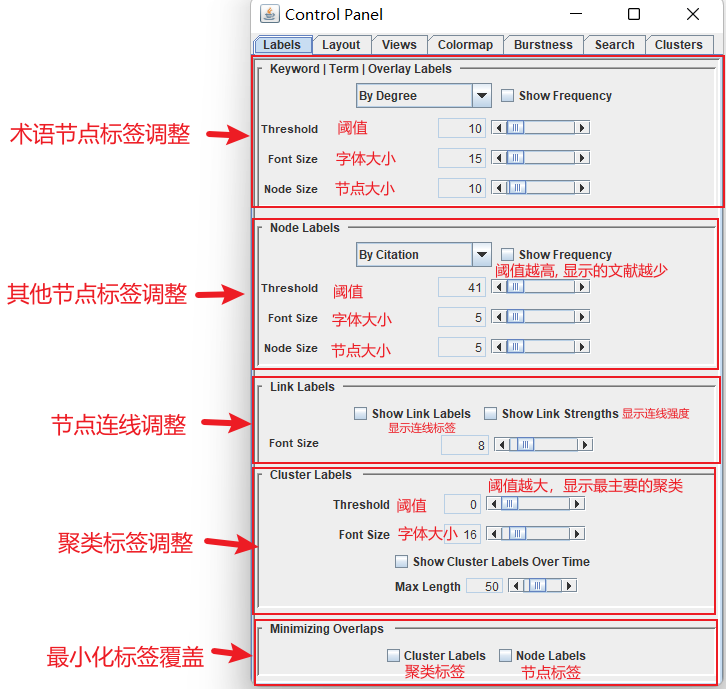
可视化图方面的调整:
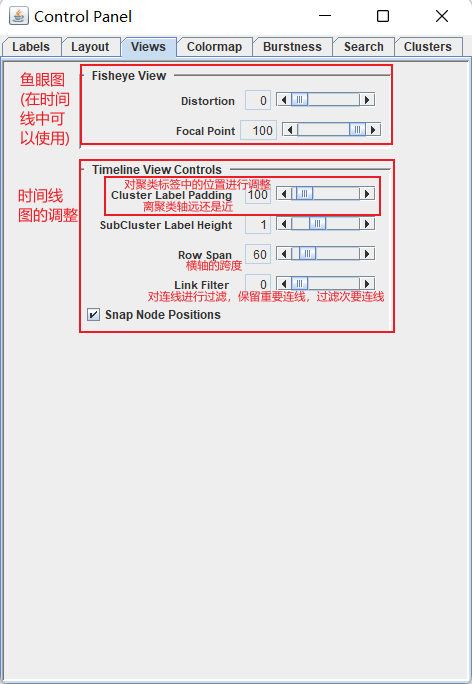
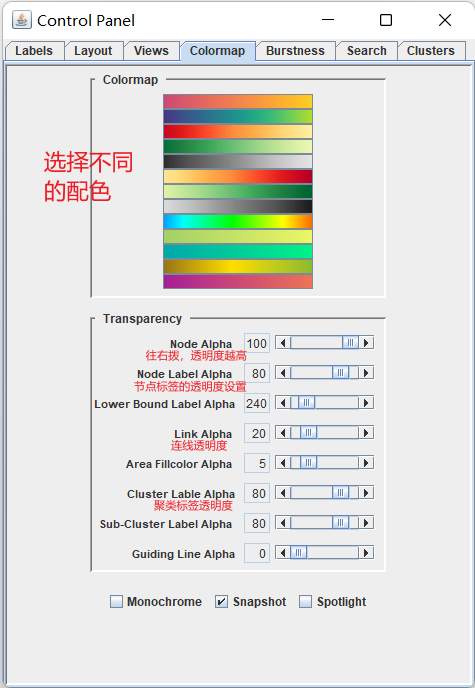
颜色以及透明度设置:
4.3.4 查看节点相关信息
选中一个节点,然后右击,如图:
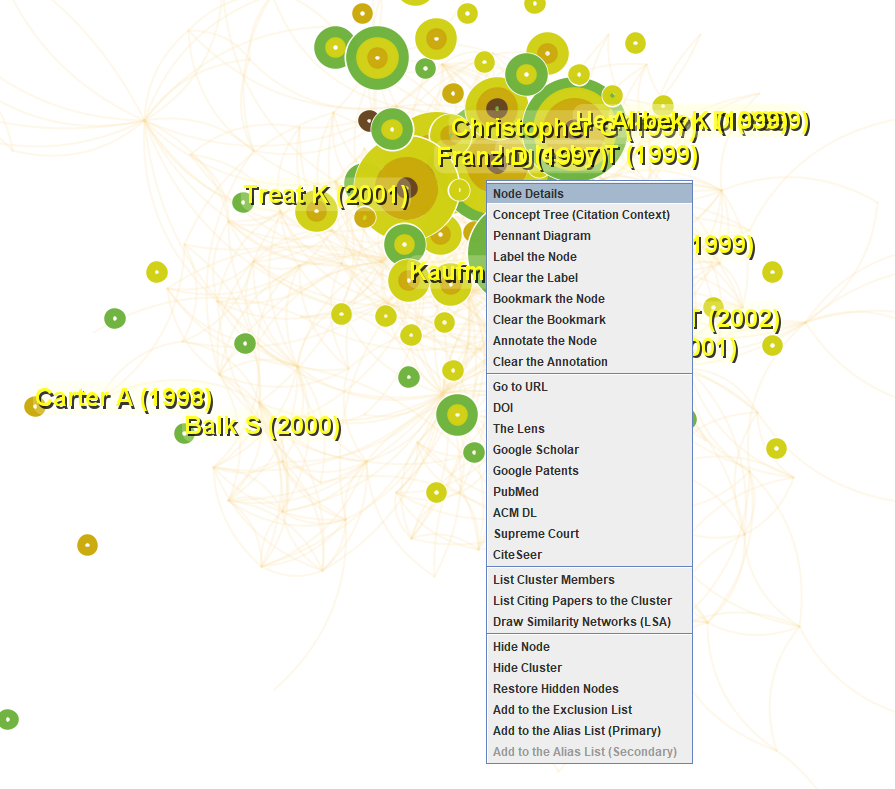
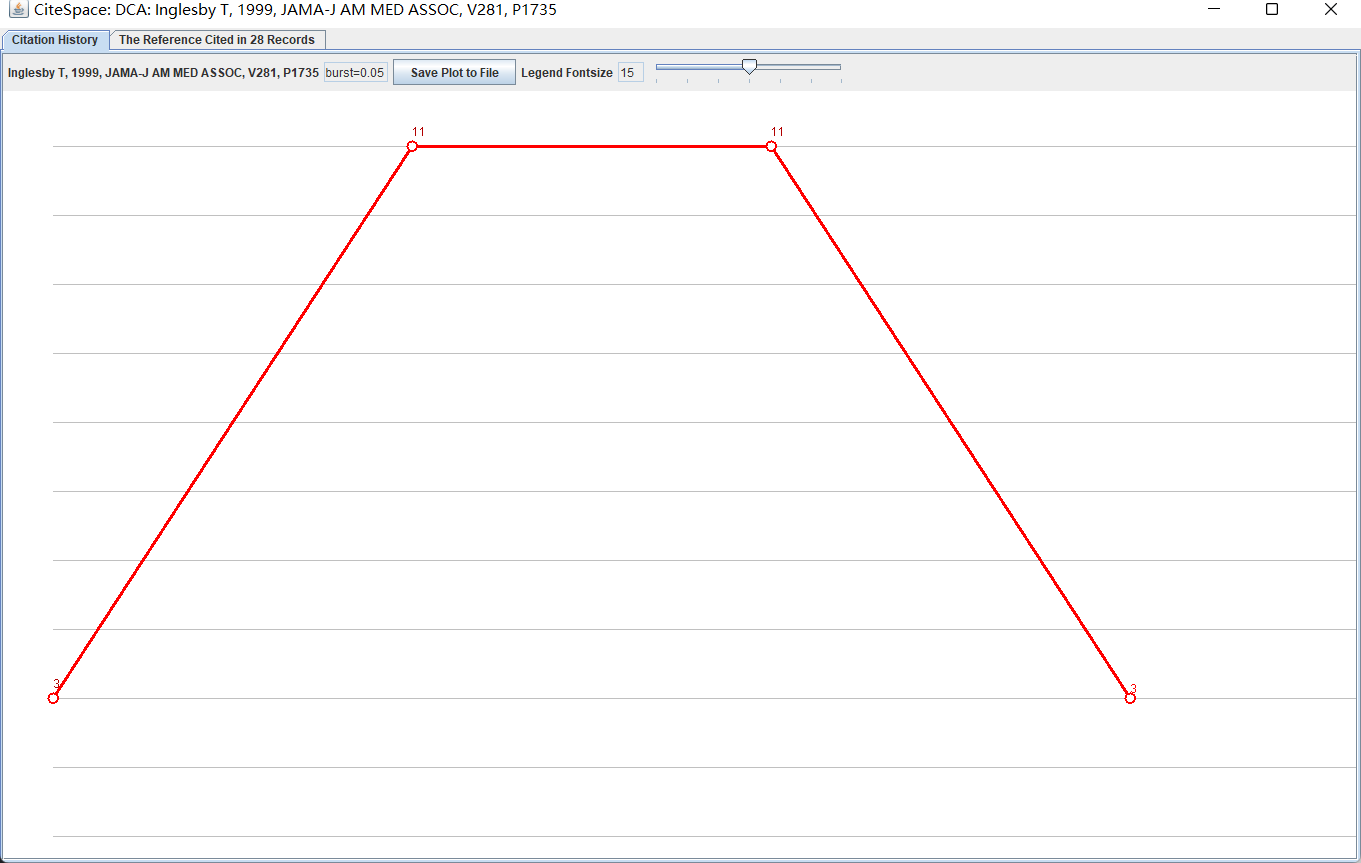
选择Node Detail,能够看到节点的被引的时序图,如下图:
右键进行节点设置:

Add to the Exclusion List:节点排除后重新运行,显示的是所选的节点被排除后的网络
如果想合并两个节点,先选中第一个节点A,然后右键选择Add to the Alias List(Primary),然后选择第二个节点B,再通过Add to the Alias List(Primary),然后再运行,B节点就会合并到A节点中。
注意:合并多个节点的时候,如果顺序被弄乱,会不成体系。
5 数据采集和预处理
5.1 Citespace分析特点
数据分析与数据组成
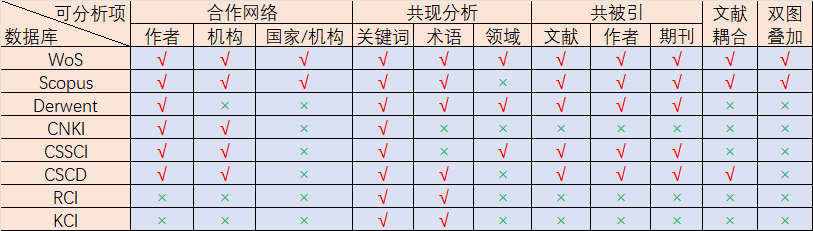
数据分析与数据内容联系密切。对于科技文本数据而言,索引型数据库的数据内容包含了除了正文以外的所有内容,而且还增加了数据库本身对论文的分类标引。
当然,不同的数据库的格式也有一定的差异性,相比而言 Web of Science 和 Scopus 的数据结构是为完整的,Derwent专利数据 和 CSSCI 次之,CNKI的完整性最小。分析中文的时候建议分析 CSSCI 的数据。
各个数据库包含的数据完整性不同,因此在CiteSpace中是不能完成有关分析的。如CNKI数据不包含参考文献字段,那就不能进行文献的共被引分析,作者的共被引分析和期刊的共被引分析。
CiteSpace分析的数据是以WoS数据为基础的,即其他数据库收集的数据都要先经过转换,成为WoS的数据格式才能分析。
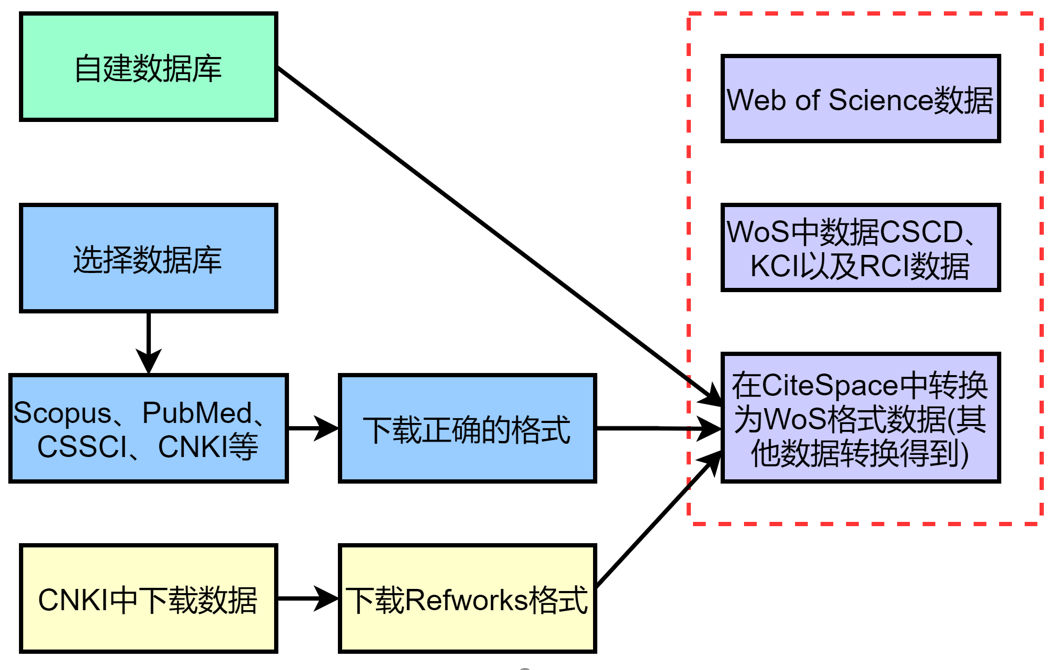
Citespace可以分析的数据类型如下所示:
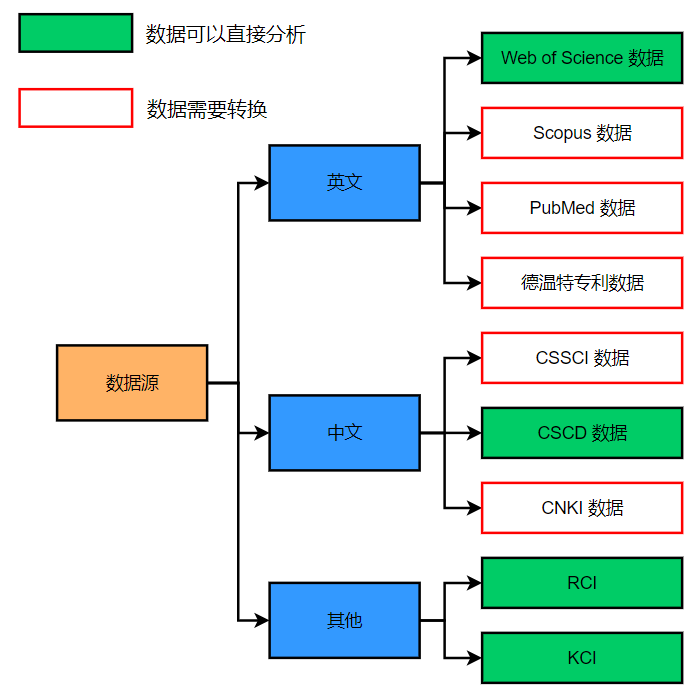
Citespace可以分析的数据源:
5.2 英文数据的采集
- Web of Science数据采集
- Scopus数据采集
- PubMed数据采集
- 德温特专利数据采集
由于每个学校的购买的数据库年限不一样,并且每个学校购买的数据库更新时间也不同,所以检索的内容可能不同。因此需要在论文中说明所购买数据库的时间范围,以及自己使用数据的时间范围。
5.2.1 Web of Science数据采集
在 Web of Science 上选择 Web of Science Core Collection 搜索库,输入关键词进行搜索,搜索后,选择导出 Plain text file 格式的文件。
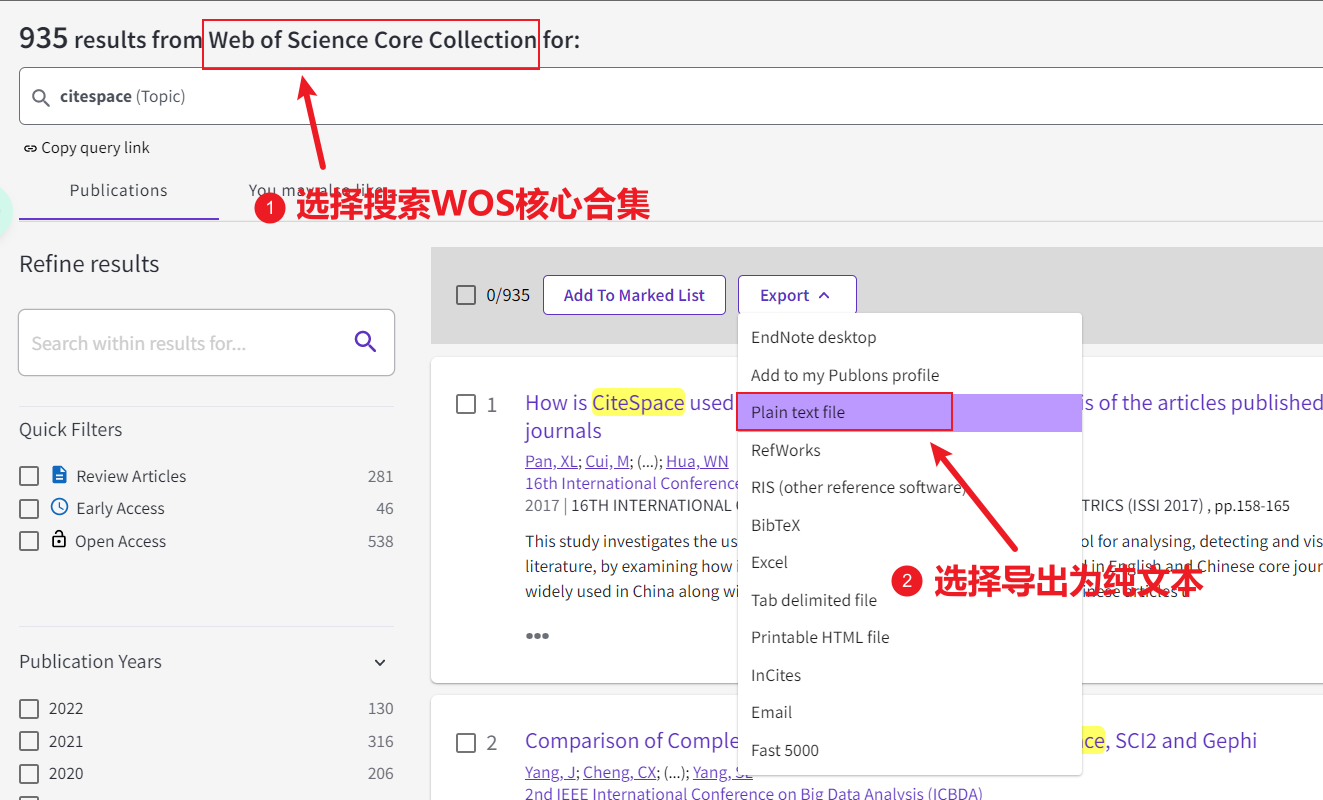
接着进行导出文件设置,如下:
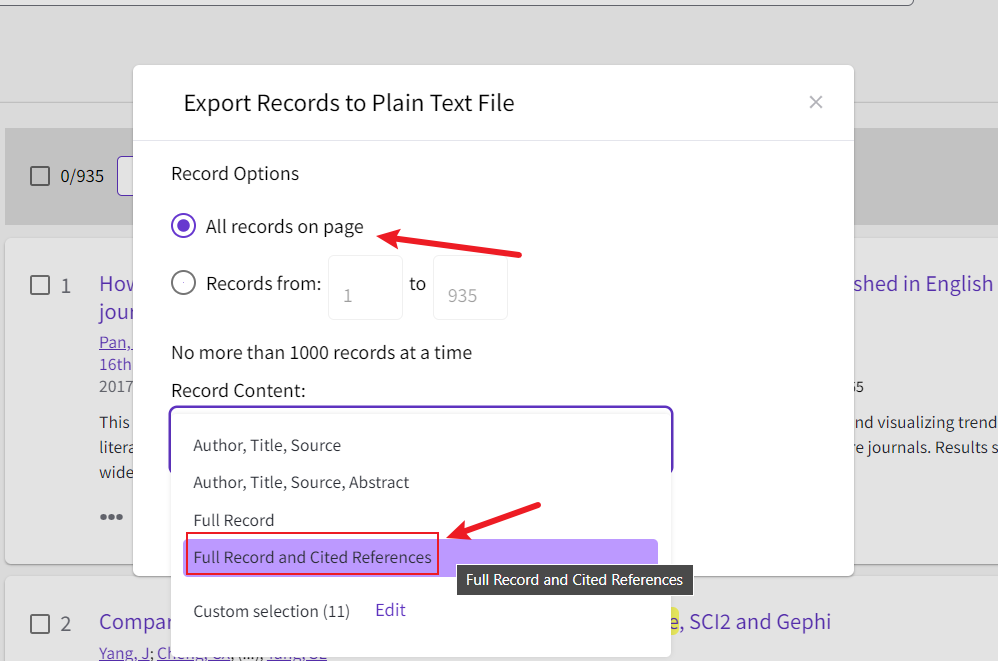
建议将下载的数据文件命名为download_501-1000.txt这样的形式。
5.2.2 Scopus数据采集
在Scopus搜索的英文界面下,搜索相应的内容,然后选择Select all然后点击Export。
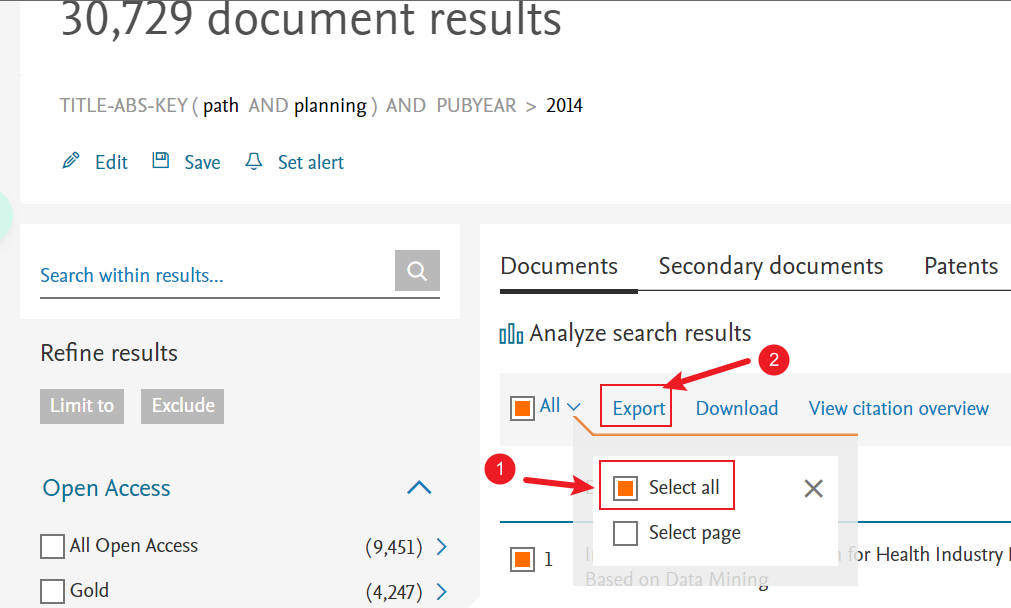
选择导出RIS Format格式,并且全选所有导出内容,并导出。
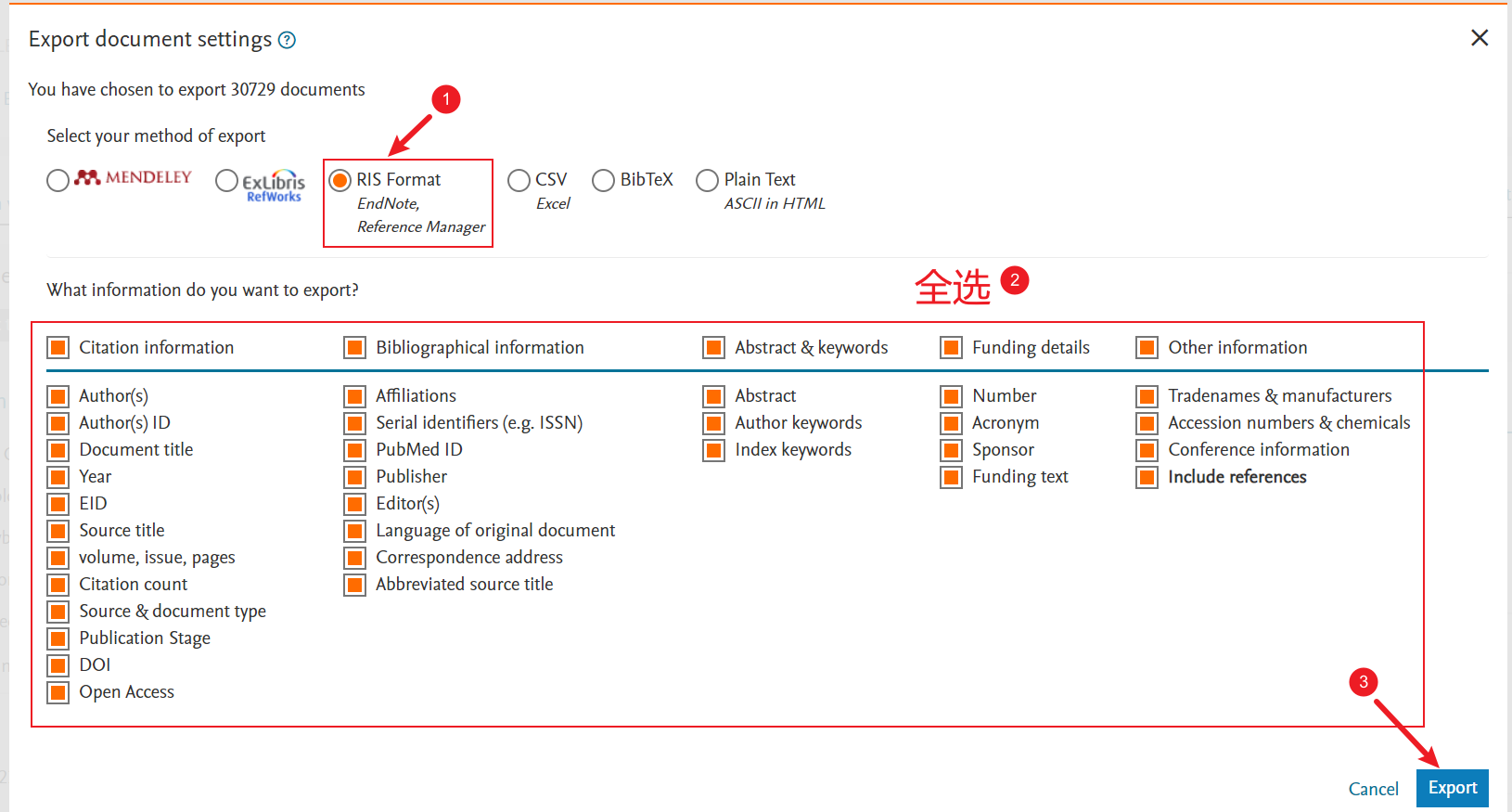
建议将下载的数据文件命名为download_501-1000.ris这样的形式。
然后将导入检索得到的ris数据:
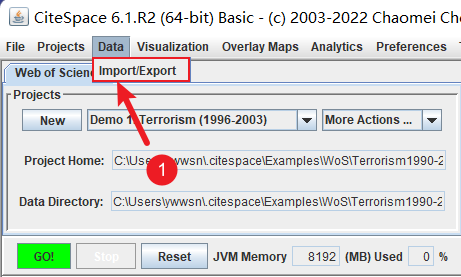
选择来源数据库为Scopus,根据如下图所示导入数据并进行转换。
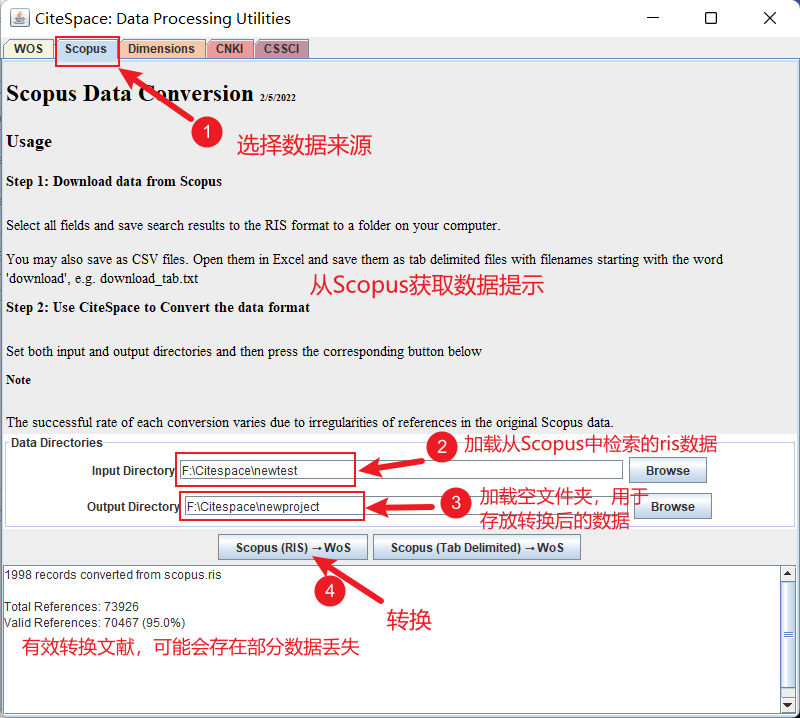
推荐首选 Web of Science 进行数据检索,否则可能会存在转换数据丢失的情况。
可以通过如下图看出ris和txt文件之间的区别:
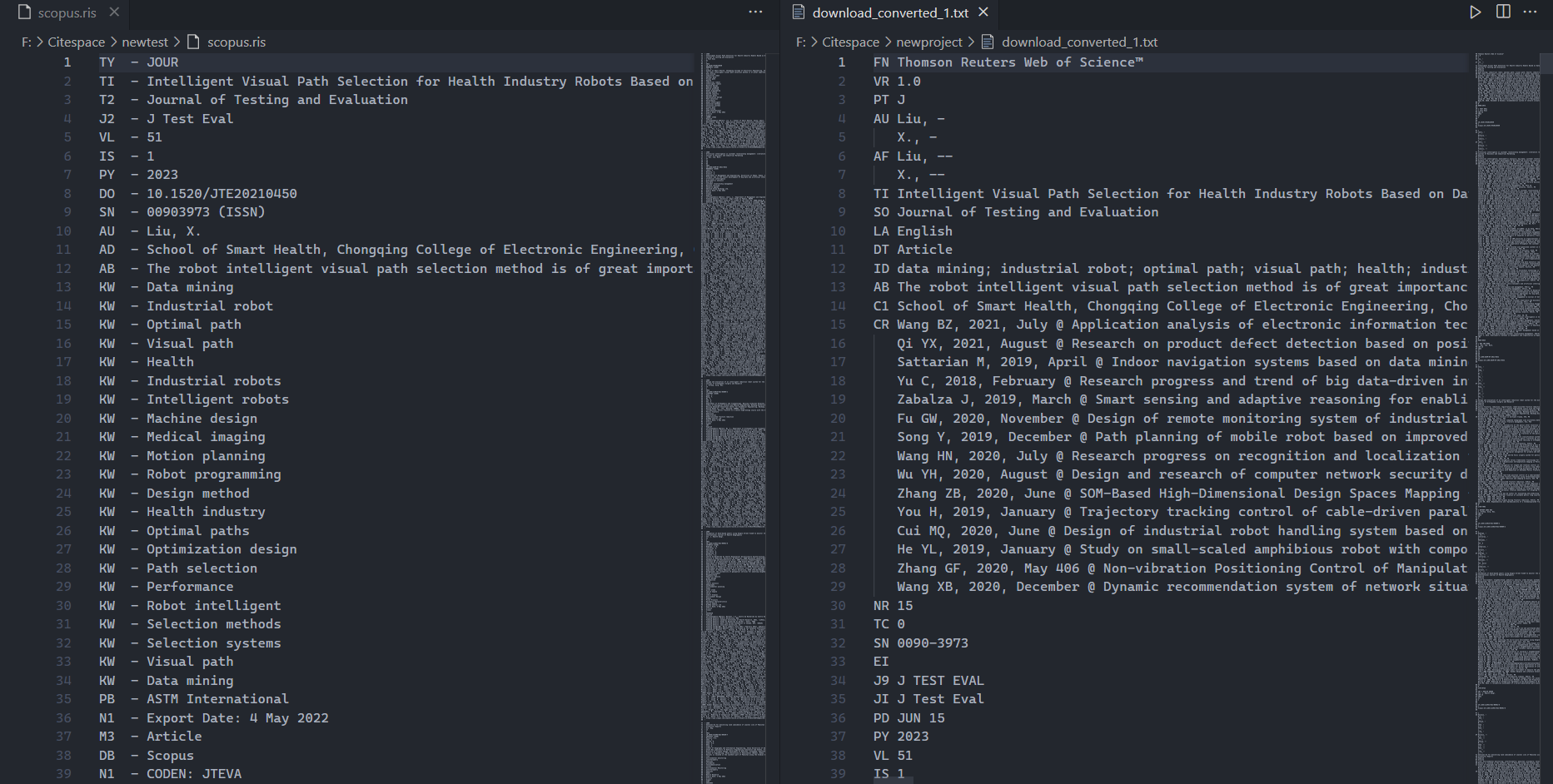
5.2.3 中文数据的采集
- CSSCI数据采集
- CSCD数据采集
- CNKI数据采集





